🔬 Research Overview
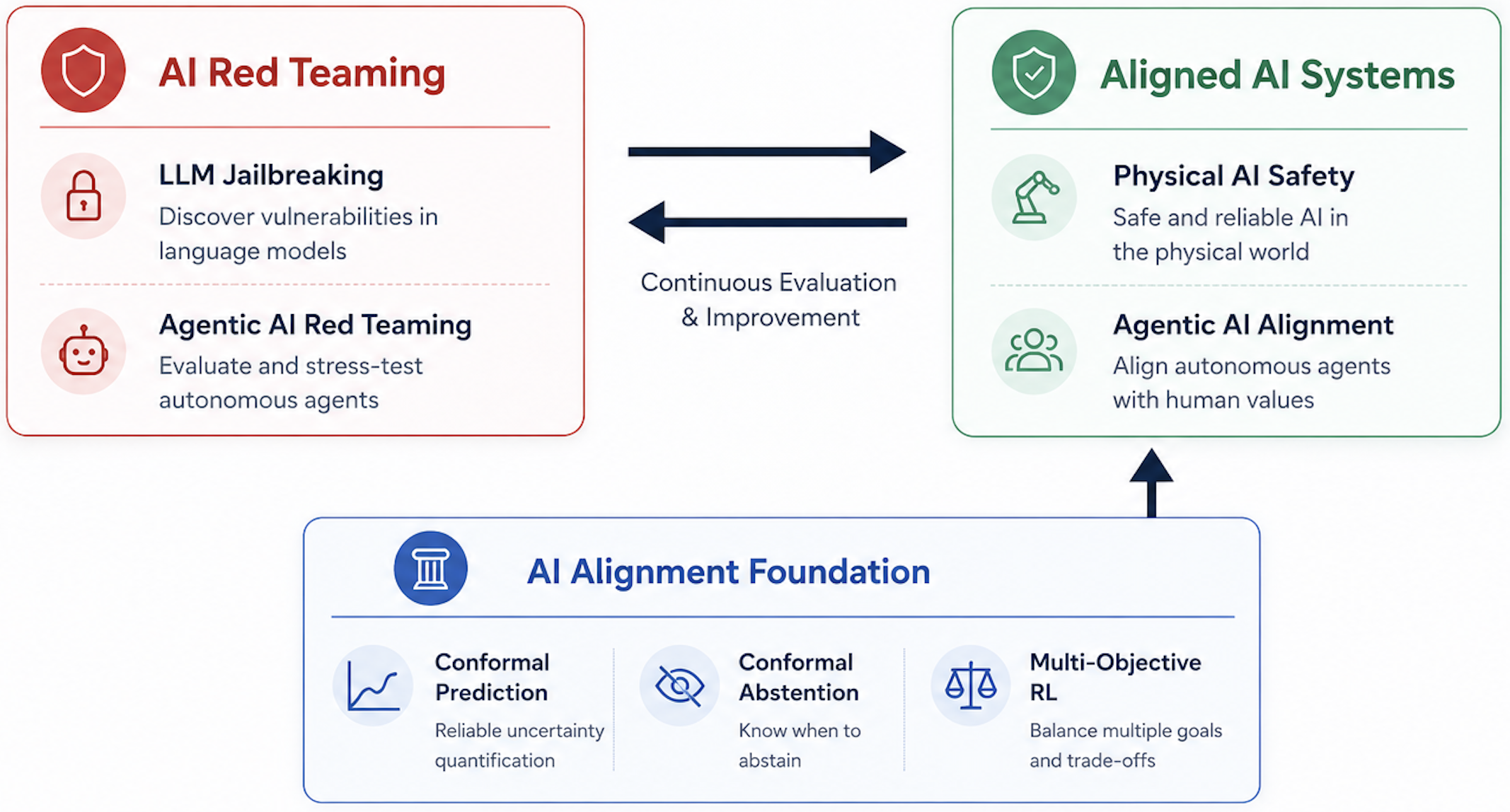
Foundations of AI Alignment
Build truthful, safe, and secure AI systems with theoretical guarantees.
Conformal Abstention
Conformal Prediction
Uncertainty Quantification
Reinforcement Learning
Large Language Models
Agentic AI
Physical AI
Agentic AI Alignment
Align AI agents to be truthful, safe, and secure.
Agentic AI
AI Alignment
Reinforcement Learning
Physical AI Safety
Live with safe robots.
Vision-Language-Action Models
Sim-to-Real Adaptation
Reinforcement Learning
Conformal Abstention
Conformal Prediction
Uncertainty Quantification
Red Teaming
Make Agentic AI better by Red Teaming.
Agentic AI
Reinforcement Learning
🤝 Sponsors




